使用Docker+Nginx部署于: quanquancho.com
Overview
In this project, we mainly discuss two major issues:
Hot dependencies in pom.xml
Tool used contribution in different countries
The architecture of the project is Vue + SpringBoot. The development of frontend and backend are splited, and as a result any of them can work separately. The interaction between the frontend and the backend are achieved through Rest API, and we use Json as the data exchange format.
In this report, we will introduce the features related to the evaluation and the structure of this project.
Project Structure
Frontend
File tree
1 | │ .browserslistrc |
Structure
The whole frontend is based on NodeJs and Vue.js framework. The intention is to create a dynamic web application that allows user interaction from web brosers for an immersive user experience, and without the need to interact with the server API to change the web content. In this project we used Windzo as a template (See sahrullahh/windzo: Free Open Source Template Dashboard Admin Vue Tailwind CSS (github.com)).
The frontend and the backend uses Rest API to communicate: The frontend uses get method to get the data from the backend server. When necessary, it also uses post method to post configurations and operations to the backend server for further actions.
1 | Navigation |
DashBoard
In this views, we implement two main scenes.
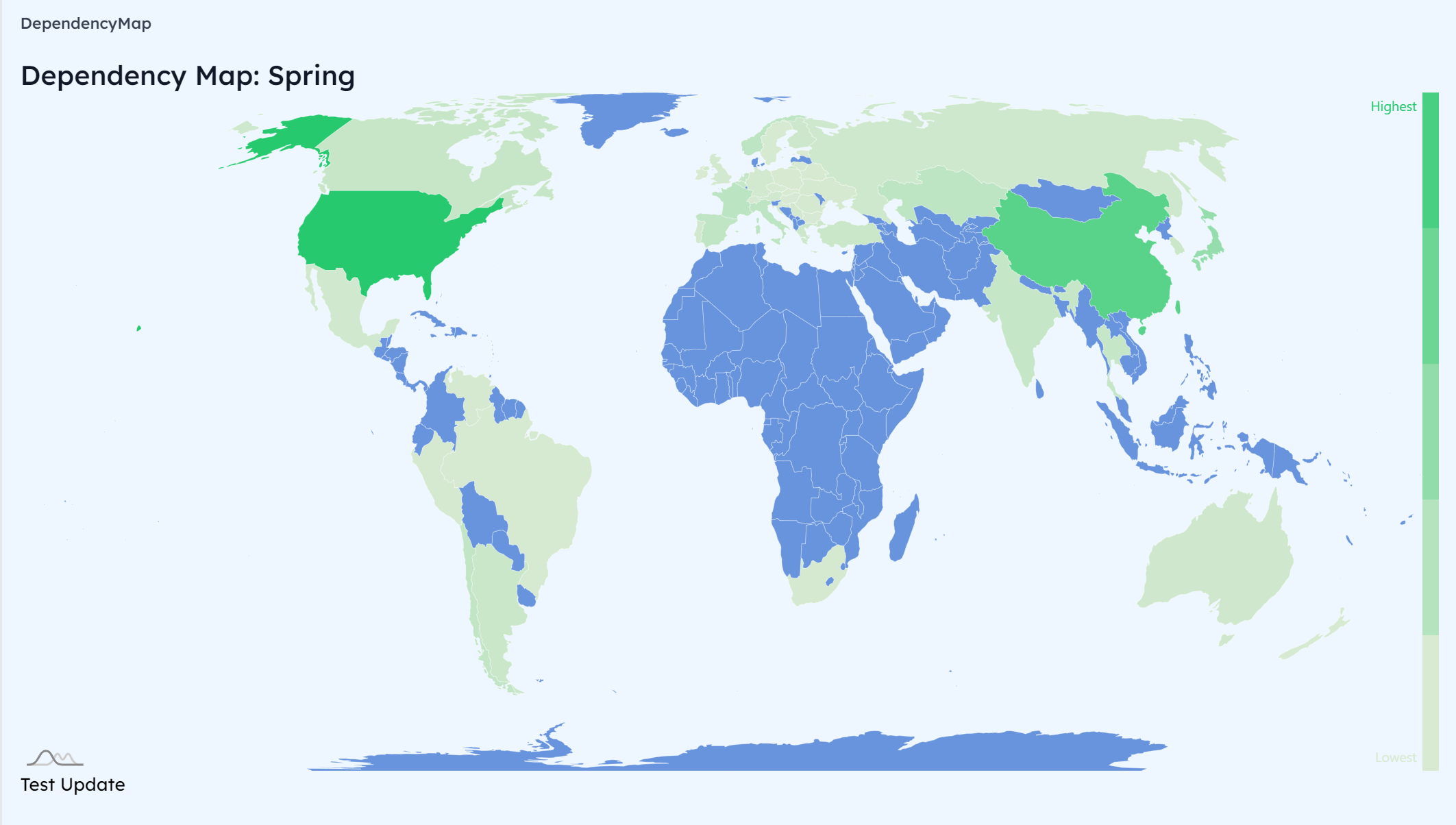
World Map
In this scene, we can choose some groupIds by some buttons, then the world map will display the number of the dependency,
which is ordered by country and each country will generate a color based on the number of dependencies. (The color will be changed by the groupId.)
Besides, we add some events in the map ,when the mouse passby some countries, it will display the amount of the dependencies of the country.
Backend
File tree
1 | ├───java |
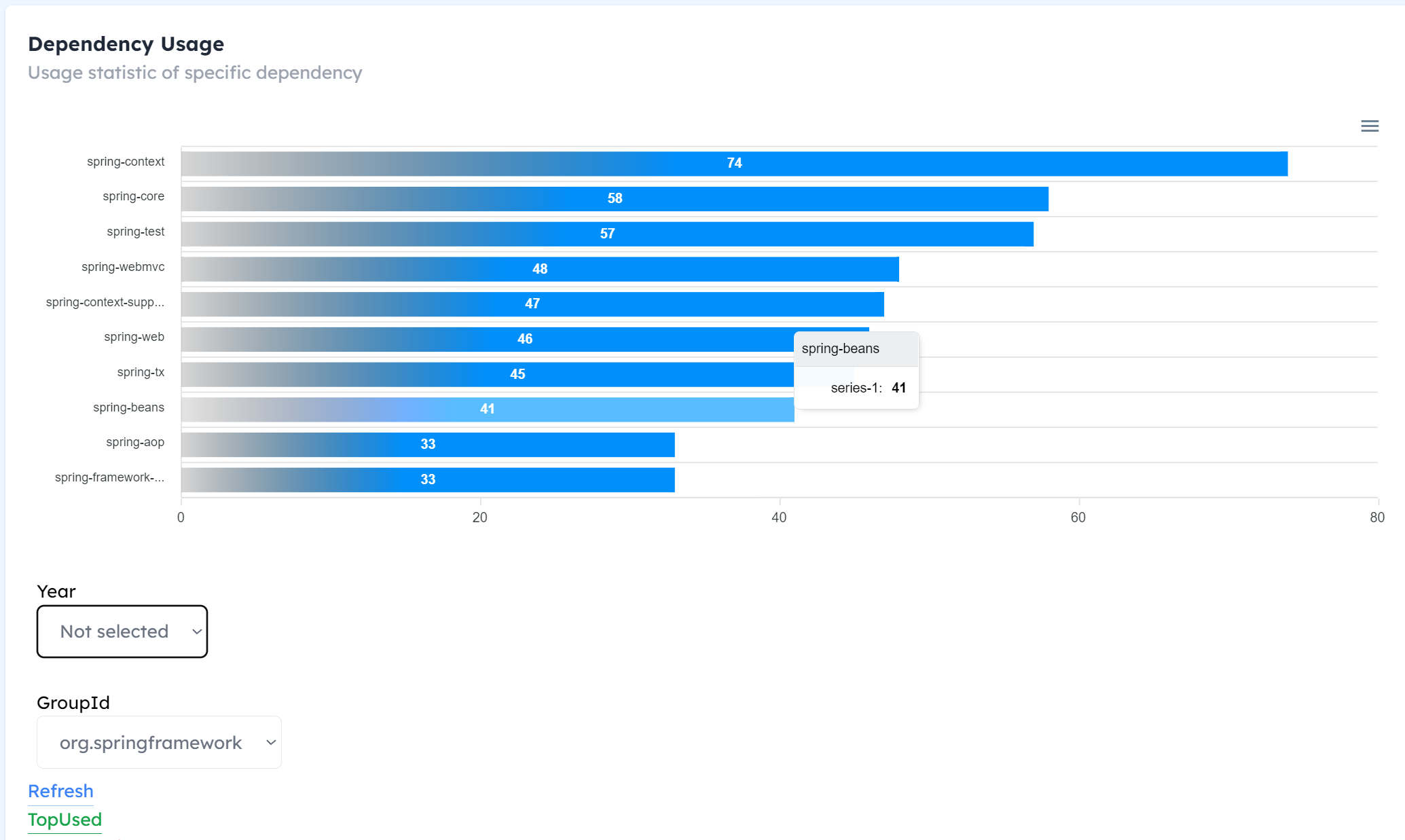
Dependency Usage
In this part, we can statics the top used dependency.
In order to improve the user’s experience, we also provide two tables for filtering. See the figure in the headers.
Controller
getTopUsedDependencies
1 |
|
This method returns the top used dependencies using specific param: group、date、count
The frontend can also set no search param to get the general result
getTopUsedVersions
1 |
|
This method returns the top used versions of specific group‘s artifact in a specific year(not neccessary) to frontend
getGroups
1 |
|
This method returns the group list that the user can select
update
1 |
|
This method updates all the data for frontend by invoking the GitHub Search Engine.
GitHub Search Engine
To make the searching process more fluently, automatically and more robust, we introduce the GitHub Search Engine.
This GitHub Search Engine has iterated several times, been published to GitHub and has till now released several packages of different versions. You can check them on IskXCr/GitHubSearchEngine: A GitHub search engine for backend application. To load the GitHub Search Engine from GitHub Packages, you may need to configure your local .m2 maven repository settings (which is typically under the Users/{UserName} folder, if Windows is considered).
File Tree
1 | edu.sustech |
Functionality & Features
The engine has a full implementation (except for acquiring Trees) of the search function of the GitHub Rest API (SearchAPI) and provides*** Java abstractions*** for dealing with entities present in GitHub (for example, Repository, User, Issues, Commits, etc. Those existing models can be found inside the models directory in the source code). It also provides additional partially implemented APIs such as UserAPI, RepositoryAPI and RateAPI for other needs such as tracing user locations and attain the information related to real-time GitHub rate limits, get the contributions of an user to a specific repository, etc.
Search requests and along with other operations can be constructed through pure Java codes and be passed to the SearchAPI or RepositoryAPI, etc. In the implementation of the SearchAPI, all http responses received and the process of parsing , error/exception processing and loop fetching (fetch until results acquired are more than or equals to the desired number of results, which is a parameter that can be either specified or left to Integer.MAX_VALUE) are hidden at default from the caller. The user of this engine is able to manipulate the interaction with the GitHub SearchEngine (without even learning the GitHub RestAPI) in a Java way and does not need to care about the inner processing and handling. Advanced manipulations of the engine can also be done with specified request parameters and through the usage of the generic methods pre-implemented.
All APIs are extended from the basic class RestAPI. RestAPI provides the basic functionality to communicate with the GitHub RestAPI, retrieving data from it, and parse the result into a required object.

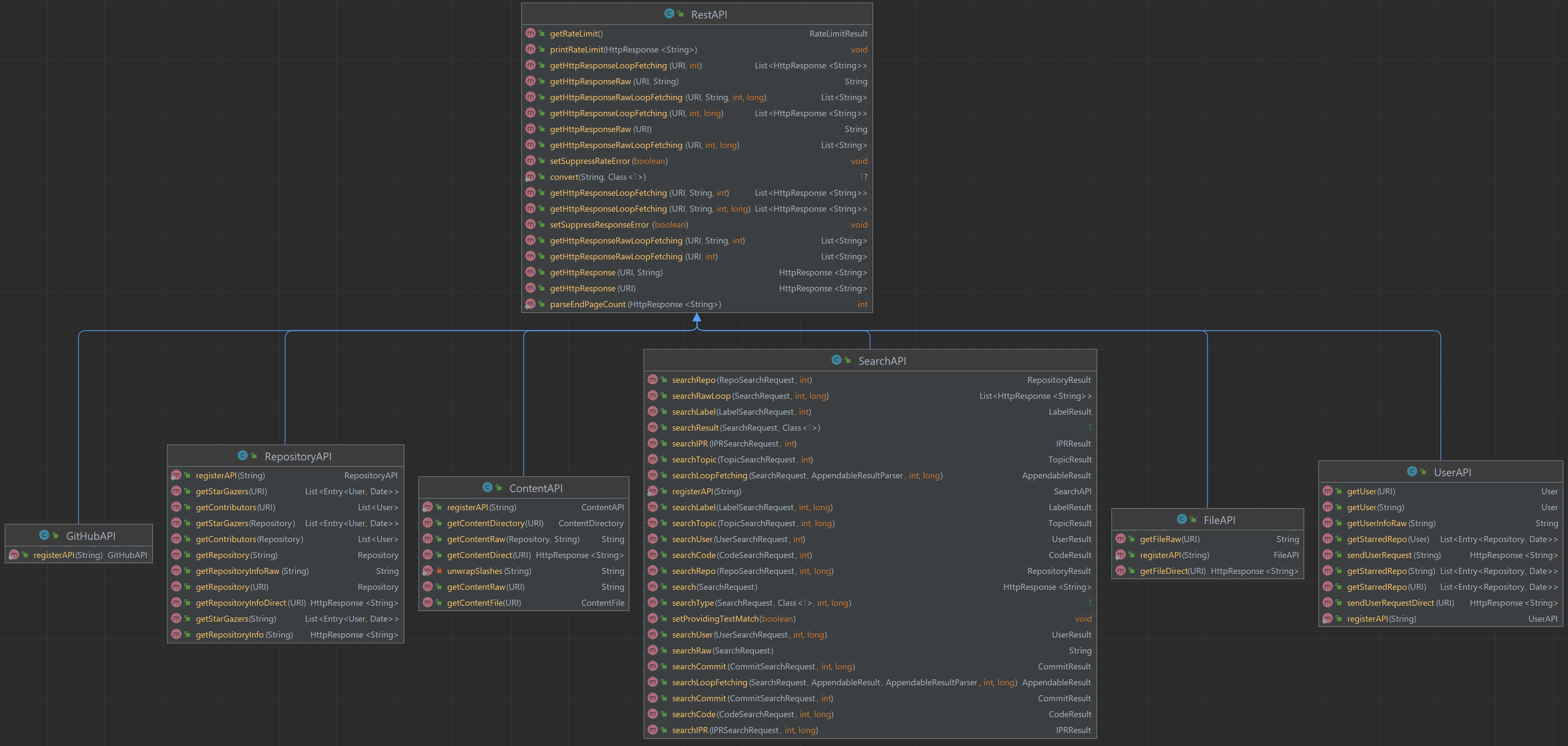
Major Implementations in the SearchAPI
searchLoopFetching method
1 | public AppendableResult searchLoopFetching(SearchRequest request1, |
This method uses AppendableResult as both one of the parameters and the result. The AppendableResultParser is an @FunctionalInterface, allowing the parsing and the manipulation of the object with unknown type.
searchLoopFetching method (Generic)
This method needs the target class to implement AppendableResult interface for combining result data from different responses.
1 | /** |
An automatical loop for dealing with the common exceptions, including timeout, RateLimitExceeded has been constructed to improve the user experience when in autonomous mode.
Basic Usage (A demonstration)
Build a request
1 | CodeSearchRequest req1 = CodeSearchRequest.newBuilder() |
Similar searches can be done on Issues, Pull Requests, Commits, Users, Repositories, RawFiles.
A detailed list on how to construct queries are listed below (the example only contains the method in CodeSearchRequest.RequestBuilder())
Similarly will we have RepoSearchRequest, IPRSearchRequest, UserSearchRequest, etc.
Note that for all SearchRequests, the methods of them have been fully implemented.
Example Usage
Search in GitHub
1 | //Register the API |
Query the results
1 | for(CodeItem item: result1){ |
Abstractions
All items related to the search part of the GitHub RestAPI has been implemented. See the file tree above to get more info.
These objects provides a basic but complex abstraction of entities on the GitHub website. At the same time, all the objects are POJOs and can be easily serialized and deserialized.
Implementation of the GitHub Search Engine (Partially)
See the source code.
Documentations
Documentations will later be generated in the format of JavaDoc directly from those JavaDoc embedded in the code. The code implements the basic methods all as generic, and users are expected to check the documents of those generic methods when encountering specific problems with the implementation of a specifc method (that is related to a certain abstraction, for example User).
Data Persistence
We use two methods for data persistence:
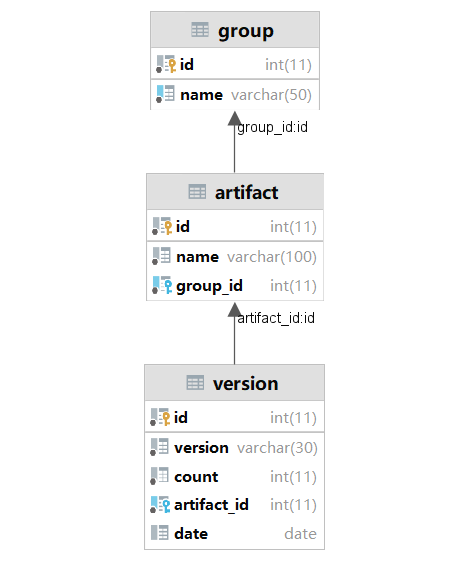
Database
We use cloud MySQL database and Mybatis ORM framework
.
Here is an dto example
1 |
|
Here is an dao example, we use Mybatis
1 | public interface VersionDao { |
1 |
|
File
Besides the database, we also use files, which stores the json data of the repo dependency information.
Dependency Analysis Insights
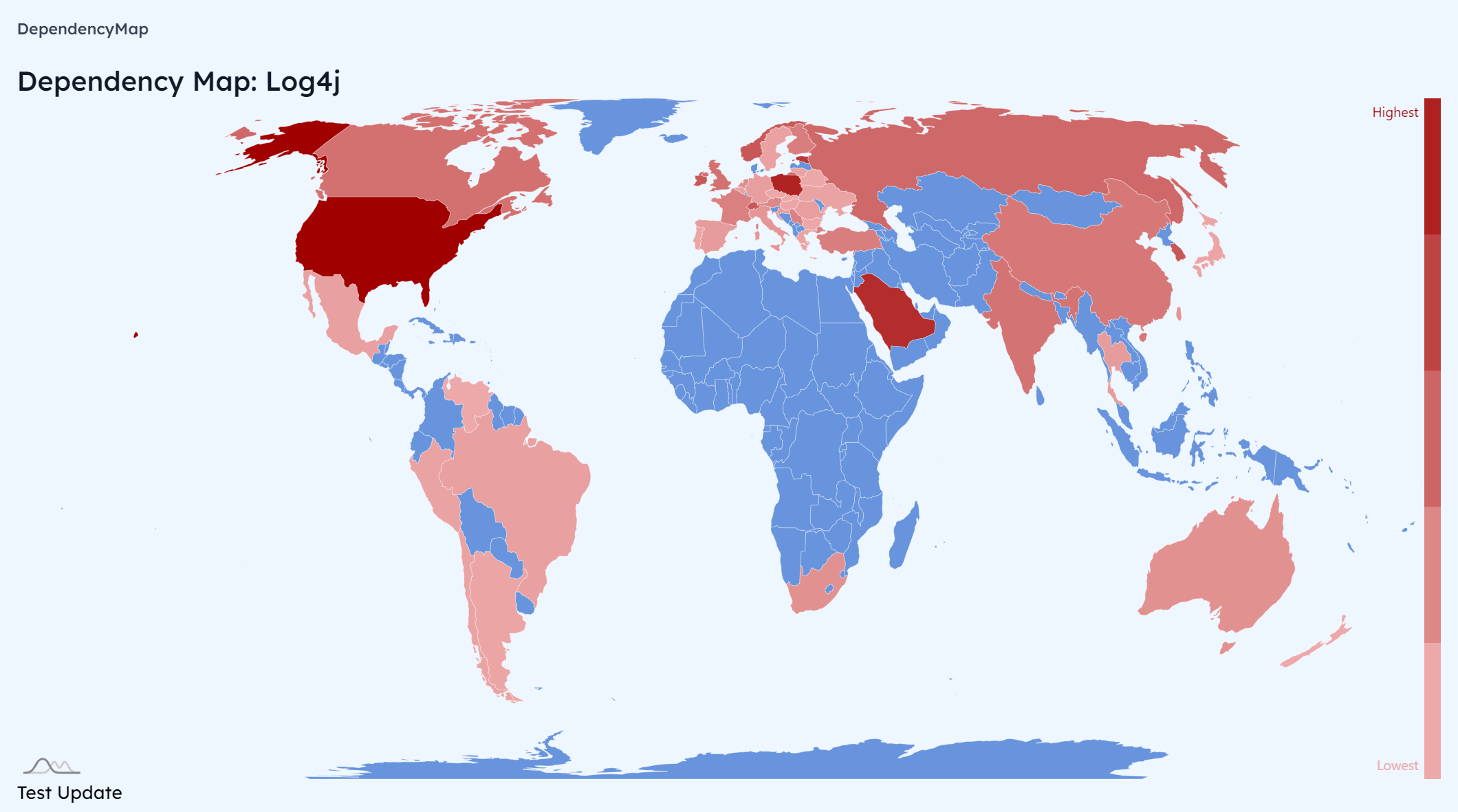
Log4j and JUnit has been the most dependencies along repositories sampled. We found that dependencies that are related to loggings and tests are widely used in the sampled repositories.
Lombok are used most frequently in China, Spring are adopted more frequently in the United States, and MySql are used quite frequently in China.
Along the sampled repositories, it seemed that developers in China prefer to use more tools related to the editing, verifying and building process of the whole lifecycle in Maven-based projects, whereas developers in the United States seems to be developing small network servers, or micro-services more (which indirectly results in the trending usage of Spring and its related transitive dependencies, along with other dependencies that provides a more frequently used result).
We found that developers are more concentrated in the European region, and that developers in China have contributed more that many western countries. People in South America has also contributed a lot, but the numbers are relatively much lower when compared to developers in China.
We found that the GitHub Rest API frequently occur secondary-rate-limitations, which is not good for web-scraping and data collection and analysis. Thus, we have only about 1000 sampled data.