为什么索引用B+树?
.
- B树
- 红黑树
- AVL树
聚簇索引 & 非聚簇索引
聚簇:数据和索引在一起
非聚簇:数据和索引分开
- .frm文件储存表结构
- .ibd(InnoDB)文件储存数据+索引
- .MYD(MyISAM)文件储存数据(D:Data)
- .MYI(MyISAM)文件储存索引(I:Index)
显然,MyISAM是非聚簇索引,而InnoDB中两者都有
InnoDB插入数据时,数据必须与一个索引放在一起(聚簇),顺序为:主键、唯一键、隐藏DB_ROW_ID
最左前缀原则
最左前缀原则是发生在组合索引上的,只有组合索引才会有所谓的左和右之分
在建立组合索引时放在最左边的字段就能享受索引的支持,即使没有单独建立索引,而不是最左边的就不能单独享受这个索引的支持了
索引下推
回表
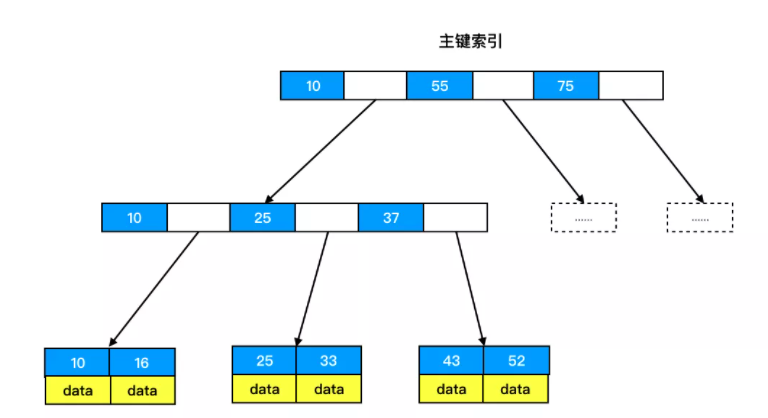
- 主键索引(聚簇):非叶子结点储存主键值,叶子节点储存整行数据
.
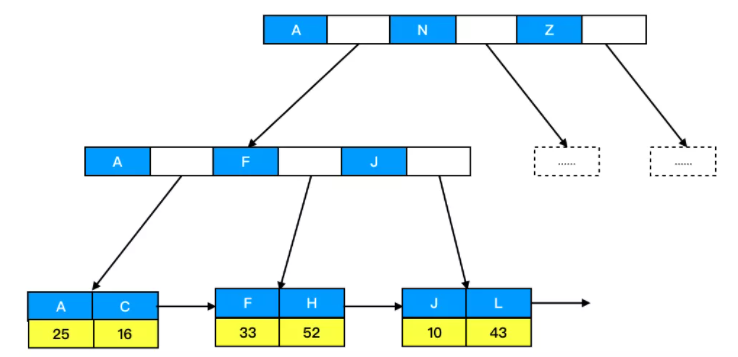
- 非主键索引(非聚簇):叶子结点储存主键值
.
回表:当我们在非主键索引上查找一行数据的时候,此时的查找方式是先搜索非主键索引树,拿到对应的主键值,再到主键索引树上查找对应的行数据。这样做的前提条件是,所要查找的字段不存在于非主键索引树上
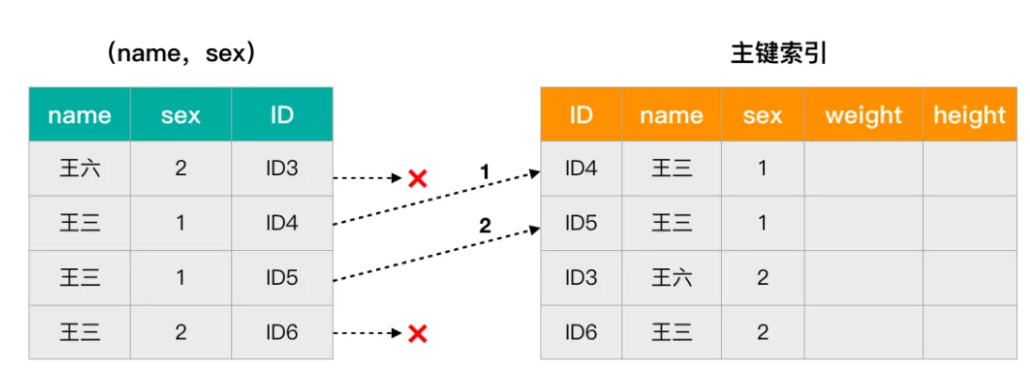
1 | 联合索引(name,sex) |
- 低版本操作:根据最左前缀原则,在非主键索引树上找到第一个满足条件的值时,通过叶子节点记录的主键值再回到主键索引树上查找到对应的行数据,再对比是否为当前所要查找的性别。每条数据都进行回表,增加了树的搜索次数
.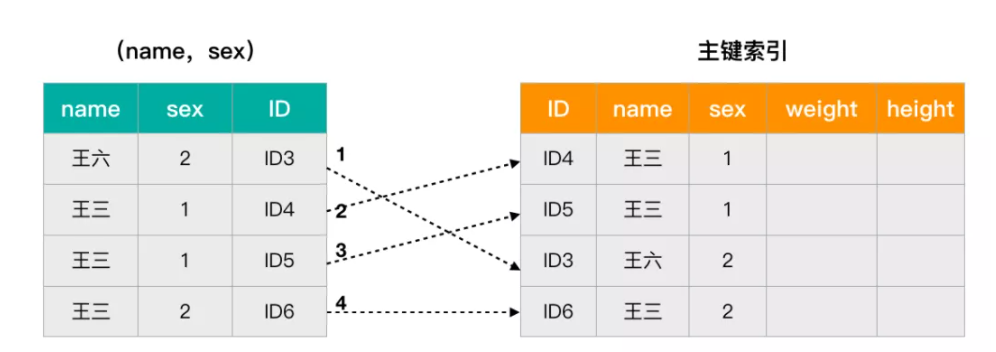
- 高版本操作:索引下推就是只有符合条件再进行回表,对索引中包含的字段先进行判断,不符合条件的跳过,减少了回表操作