文章 https://mp.weixin.qq.com/s/1yWSfdz0j-PprGkDgOomhQ 的学习笔记
为什么要ConcurrentHashMap?
即使JDK1.8的HashMap已经不会出现环形链表,但仍然线程不安全
.
例如,若多个线程同时执行put方法,可能会同时进入第627行的判断条件,发生更新覆盖的情况
解决HashMap的并发问题,可以使用HashTable或Collections.synchronizedMap,但两者在读写时都会对整个集合加锁,性能很低
什么是ConcurrentHashMap?
ConcurrentHashMap由大小为$2^n$的segments数组组成,不允许key为null
put和get方法都需要两次定位,利用hash值,先定位到segment,再定位到entry
.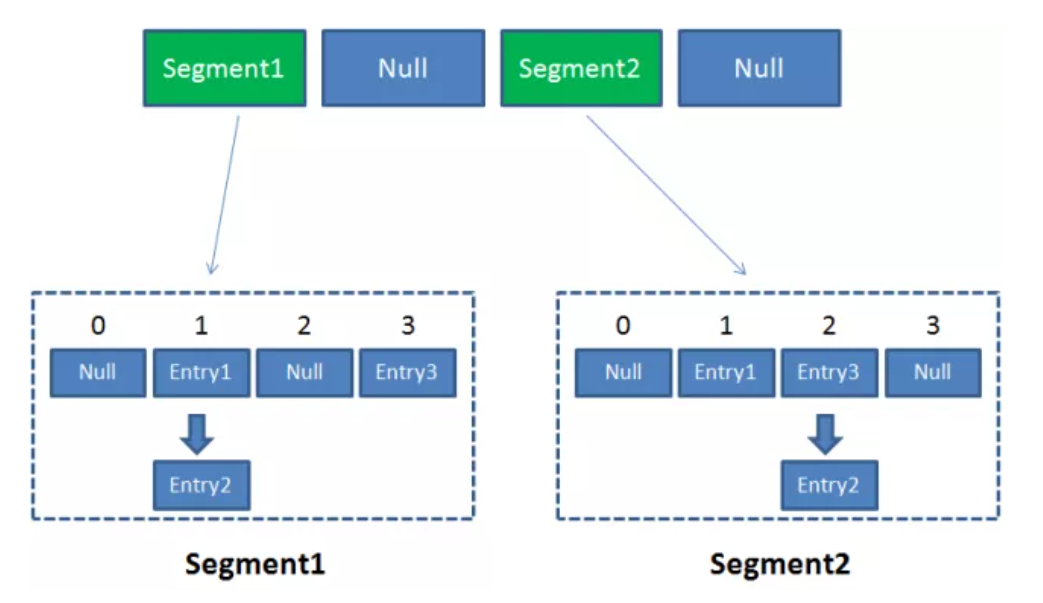
不同segment的操作互不影响👆
.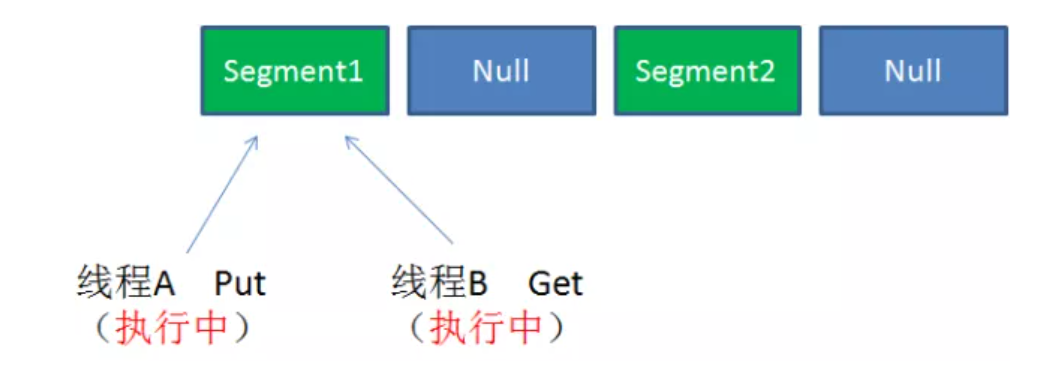
同一segment的读写是并发的👆
.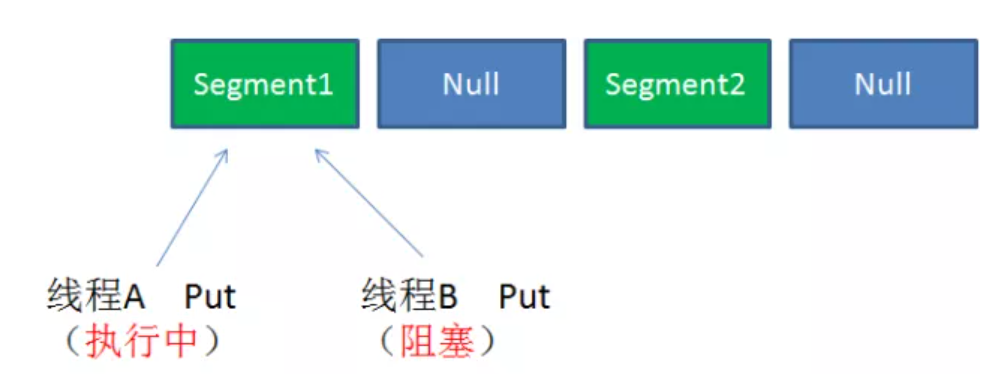
同理,同一segment的写写需要阻塞👆
size()方法如何保证线程安全?
ConcurrentHashMap的size()方法是一个嵌套循环,大体逻辑如下:
1.遍历所有的Segment
2.把Segment的元素数量累加起来
3.把Segment的修改次数累加起来
4.判断所有Segment的总修改次数是否大于上一次的总修改次数。如果大于,说明统计过程中有修改,重新统计,尝试次数+1;如果不是,说明没有修改,统计结束
5.如果尝试次数超过阈值,则对每一个Segment加锁,再重新统计
6.再次判断所有Segment的总修改次数是否大于上一次的总修改次数。由于已经加锁,次数一定和上次相等
7.释放锁,统计结束
可以看出,先是乐观锁,无奈后转为悲观锁
JDK1.7和1.8的区别
| JDK1.7 | JDK1.8 | |
|---|---|---|
| 结构 | ReentrantLock+Segment[] | synchronized+CAS |
| 锁粒度 | Segment | HashEntry |
JDK 1.8 的ConcurrentHashMap不再有 Segment 的概念,不再使用分段锁,而是给数组中的每一个头节点(桶)都加锁,锁的粒度降低了,并且用的是 synchronized锁
其余的区别与JDK1.7和1.8的HashMap相同